Summary
With the rise of the Internet and social media, information has become readily accessible across the globe nowadays in a matter of seconds. However, despite all the positive impact technology has on our society, misuse of its power can potentially result in negative repercussions. The increase in accessibility to information has allowed misleading content to propagate all over the web at unprecedented rates.
In this analysis, we study the potential power of artificial intelligence in the fight against the dissemination of fake news by exploring various machine learning algorithms. Given the imbalance in the number of fake news compared to real ones, we analyzed the effect of tuning the class weights during training. According to our experiments, by comparing the performances of different models, we found that LSTM yielded the best result at classifying binary true and false quotes with an accuracy of \(0.72\). Likewise, LSTM also generated the best accuracy of \(0.31\) for multi-class predictions. For weighted classes, SVC produced the highest recall for true quotes at \(0.59\). The results show that adjusting the weights can help improve the prediction of the underrepresented classes, at the cost of a slightly lower overall performance.
Table of Contents
Introduction
In today’s digital era, information circulates very quickly. Through a combination of technological advancements, the creation of the Internet and the birth of social media, the world has become more connected than ever. The accessibility of information online allows us to remain up-to-date with global news and to communicate with others across the world. However, this new-found convenience and accessibility to information also introduces unprecedented challenges. Dissimulated in the abundance of different news outlets and media platforms, fake news is becoming increasingly pervasive on the Internet. A moment of negligence can result in falling prey to the trickery of dishonest parties. Therefore, critical thinking and media literacy are essential components to the fight against fake news. With that being said, relying solely on our ability to detect false information might not be enough.
If technology can be used in the dissemination of fake news, it can also be utilized in the fight against it. Albeit an imperfect solution, the use of artificial intelligence can help mitigate the risks of falling victim to fake news through the detection of potentially false information circulating online. Reputed fact-checking organizations can also be a valuable source of information which could assist in the prediction of fake news, given that statements are manually verified and backed with credible sources. Hence, we will explore Politifact, a fact-checking website that reviews statements and provides a spectrum of labels (True, Mostly True, Half True, Barely True, False and Pants on Fire) describing the truthfulness of a given political quote3.
Related Work
The rise in propagation of fake news online is considered a potential threat to our society. Many fake news detection research projects have been conducted in recent years in order to slow down the spread of false information. According to the literature, machine learning algorithms are suitable for this type of problem given their classification and prediction functionalities17. Several different datasets from reputed fact-checkers such as Snopes are available with manually categorized labels, whereas raw data can also be obtained through the API’s of major social media platform like Twitter. For instance, researchers have investigated fake news from Facebook, employing machine learning algorithms such as the Naive Bayes classification model to predict the legitimacy of a news8. In this post, we explored other experiments that specifically analyzed data from Politifact and referred to their results as benchmark.
Liar, Liar Pants on Fire
In this study, a dataset collected from Politifact known as the LIAR dataset was used in the experiments. At the time, the dataset consisted of 12,836 quotes along with information related to the subject, the context or venue, the speaker, the party, etc.18 Several classifiers were selected as candidates in the experiments including SVM, Logistic Regression, Bi-LSTM, CNN and others. Hybrid-CNNs were also tested with different combinations of features, such as the quote with the subject, the state, or with all features. The results showed that Hybrid-CNN with the feature speaker yielded the best accuracy at 0.277 in the prediction of the multi-class labels. The results from this experiment can be used as benchmark for our own tests, since it provides an expected range of values in which the performance of our models should fall within.
FakeNewsNet
Another analysis collected data from Politifact and GossipCop, including social context and spatialtemporal information15. User profiles, posts, responses and networks were some of the elements explored under the hypothesis that there exists a correlation between social context and fake news detection. In this study, Politifact statement labels were used as ground truth while collecting the news content from different sources. The results showed that the usage of Social Article Fusion (SAF)14 which utilizes autoencoders to learn the features generated the best accuracy at 0.691. For our experiments, we can further explore the concept of contextual features and integrate additional external information pertaining to the author or context of each quote.
FAKEDETECTOR
The following research study introduces a novel automatic credibility inference model for fake news called FakeDetector which uses a variety of classical machine learning and deep learning algorithms19. In addition to the multi-class classification of the quotes from Politifact, a binary label was derived from the original classes by grouping (True, Mostly True and Half True) as True and (Barely True, False, Pants on Fire) as False. The performance obtained from FakeDetector was around 0.63 and 0.28 for the binary and multiclass classification respectively.
Methodology
Dataset
The data collection process involved crawling the Politifact website for the quotes, along with the labels, author, context, date and affiliation. The raw dataset was comprised of 18,053 rows with 8 columns which included label, quote, context, author_id, author_name, date, categories and staff. Exact duplicates of the statements were discarded while other page link issues were identified and resolved. Additional data was also retrieved regarding the authors such as their name, affiliation and description for a total of 4,610 unique entries.
Data Exploration
Firstly, we explored the historical data collected from Politifact in order to better understand the nature of the data and its distributions. For instance, we noticed that only post-2007 quotes were classified into all 6 categories, as there were only False and Barely True quotes prior to that year as shown in Figure 1. Another observation pertains to the significant rise in the number of False news in recent years.
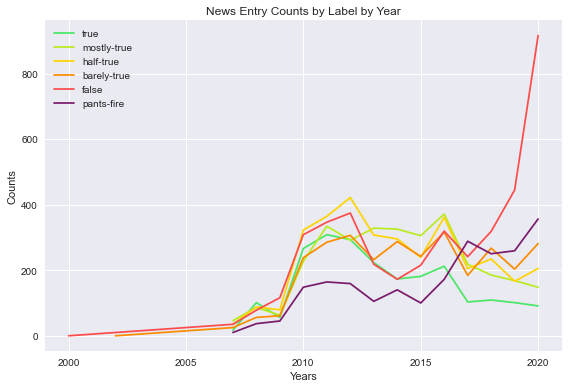
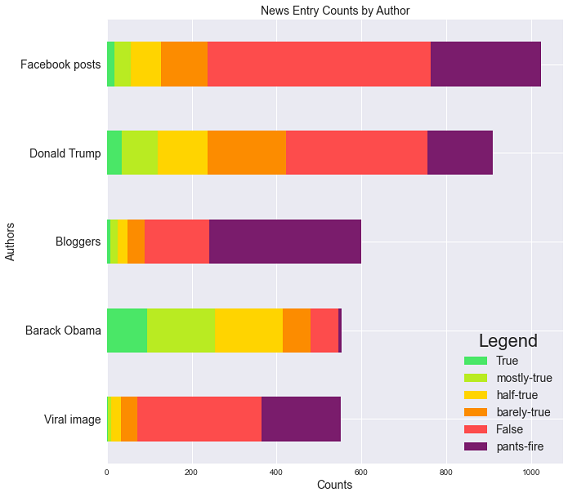
Next, we analyzed the number of statements for each label to better understand the distribution of the target variable in this classification problem. The False statements were the most frequent whereas Pants on Fire the least. We also visualized the most frequent authors of quotes from the Politifact data and the breakdown by classes, as illustrated in Figure 2.
Preprocessing
Before training the models, we preprocessed the data by cleaning and standardizing it. For instance, we simplified the context variable by grouping entries from the same class such as "tv commercial", "tv ad" and "an ad on tv". It helped reduce the number of unique contexts from 5,986 to 279. We further decreased the dimensionality of this feature by assigning contexts with fewer than 10 occurrences to the category other, which ultimately reduced the number of unique contexts to 76.
Regarding the textual data of the quotes, we applied preprocessing steps to standardize the text with the help of the nltk library. Stopwords were removed from the statements, the text was set to lowercase and all punctuation was discarded. Moreoever, we included the lemmatization process in the preprocessing of the quotes to group words together by their lemma. Finally, we vectorized the textual information using 2 methods. The first method was to transform the data into vectors of numbers by using the TF-IDF vectorizer, which captures the importance of each word relative to the entirety of the corpus. The second one involved the usage of Word2Vec9 , a popular word embedding technique, to transform each word into a vector of numbers. The main functionality of word embedding is that the output vectors of 2 words that can be used in similar contexts will have close values.
Feature Engineering
In terms of feature engineering, we first derived text related features including the number of words in the quote, the number of characters in the quote, the average word length, and the number of stopwords in the quotes. The numerical values are further normalized with MinMaxScaler from sklearn such that the range is between 0 and 1.
Furthermore, we used the gender-guesser library to infer the gender of each author1. The default 5 categories are male, female, mostly male, mostly female and androgynous. An additional category unknown was created for organizations or entities which cannot be assigned a single gender. However, given the imperfection of the tool, we also leveraged each author’s short personal description to correct mis-classified genders. For example, if the description only contained male pronouns, there was enough evidence to assign the gender male. At the end, our dataset was comprised of 2387 males, 1312 unknowns, 750 females, 90 mostly males, 52 most females and 17 androgynous.
In addition to the multi-class outcome variable, we also explored the binary version of the fake news classifications by Politifact. The labels (True, Mostly True) were grouped together as True, while (Half True, Barely True, False, Pants on Fire) made up the class False.
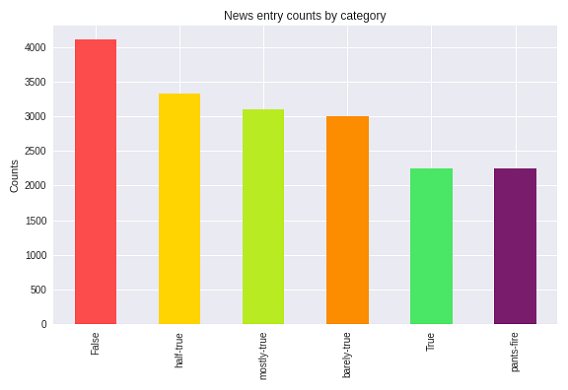
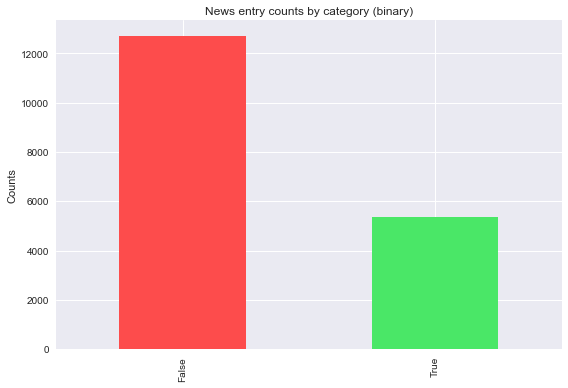
As shown in Figure 3, the Politifact dataset is imbalanced, as there were a lot more False than any other category, which resulted in an underrepresentation of the True and Pants on Fire categories, which can potentially be problematic as observed further in our results. Likewise, this imbalance can also be seen in Figure 4 with the binary categories. The disparity between False and True was even further emphasized in the binary classes, illustrated by the noticeable difference in frequencies between both categories of quotes.
Models
For our baseline model, we decided to use the Multinomial Naive Bayes classifier as a benchmark given its ease of implementation and quickness to train. It also works well with high dimensionality spaces such as text classification problems.
Logistic regression was another algorithm included in our test, as it is a probabilistic classification model widely used across different fields7. It is easy to implement, does not rely on extensive assumptions and can be extended for multi-class classification purposes.
Random Forest was also a candidate model, a popular machine learning algorithm which has seen a lot of success in various domains in recent years13. It is easy to interpret, functions with large datasets and less sensitive to outliers.
Support Vector Machine (SVM) was another machine learning classifier we included in our experiments. It handles high-dimensional spaces and functions well when clear boundaries are defined4.
In addition to the classical machine learning models mentioned above, we implemented 2 Deep Learning algorithms: Convolutional Neural Network (CNN) and Long Short-Term Memory Neural Network (LSTM) which is a derivative of Recurrent Neural Network (RNN). CNN is one of the most popular deep learning architecture and its main advantage would be the ability to automatically detect the important features without any human supervision5. The strength of LSTM is that it is capable of analysing sequences of data which can be very powerful if mixed with word embedding16. In essence, the algorithm maintains a memory state capturing the history of the sequences of words, preserving important information throughout the parsing of the sentences.
Feature Selection
Our approach consisted of measuring the performance of the models by only including the vector representation of the quotes as the input features. For the TF-IDF transformations, since the vocabulary size of the corpus was fairly large, the text was represented as sparse matrices to handle the high dimensionality of the feature space. We also tried to transform our input using Word2Vec, but it gave us better results only when used alongside LSTM or CNN10, 11.
Then, we added additional features and evaluated the impact of each feature on our results. Variables including the author, the affiliation, the context and others were one-hot encoded and included as input to the models. The features were selected based on their level of importance and correlation with the target variable, information obtained through sklearn’s SelectKBest function along with a chi-square scoring scheme.
Web Application
Once the models were trained and performance results were obtained, we implemented a web application built with the Flask framework. We designed a user interface allowing users to enter a quote as well as other contextual information such as the author, the context and so on. The information is then used as features to predict the veracity of the statement. The models from our experiments were trained and exported through Python’s object serialization library pickle to avoid repeatedly having to re-train the model during application usage2. Essentially, the application offers a user-friendly interface for users to fact-check political quotes. It is important to note that the web application is simply a prototype and proof-of-concept, and that performance is only guaranteed for quotes from Politifact.
Results
Multi-class Classification
For the classification between the 6 different categories of quotes, we measured and compared the accuracy of each model as shown in Table 1. The Multinomial Naive Bayes model used as baseline performed the worst with an accuracy of 0.28, whereas LSTM was the best at 0.31.
| Models | Accuracy |
|---|---|
| Naive Bayes | 0.283 |
| Logistic Regression | 0.294 |
| Random Forest | 0.286 |
| SVC | 0.295 |
| CNN | 0.293 |
| LSTM | 0.310 |
Exploring the impact of weighted classes, we repeated the experiments by adjusting the class_weight parameters in most algorithms. We only presented the results from the LSTM model given it was the one with the highest performance, but the other algorithms showed similar behavior when balancing the classes.
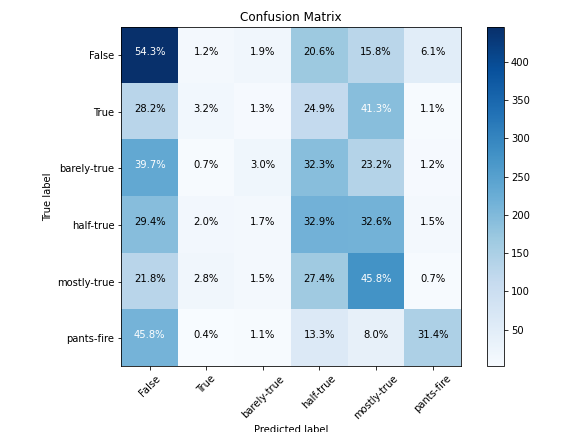
The confusion matrix in Figure 5 shows the percentage of correctly predicted quotes in each of the categories. The majority of data was predicted as either False, Half True or Mostly True, which corresponds to the most frequent types of quotes. The rest of the categories with lower frequencies were rarely predicted correctly, with percentages as low as 3.2% for True and 3.0% for Barely True. Despite being the most underrepresented class, Pants on Fire fared better at 31.4% than the previous two categories.
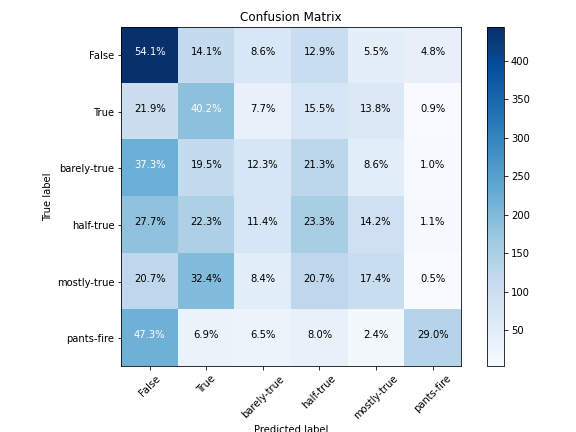
In comparison, the confusion matrix in Figure 6 illustrates a more balanced distribution of correctly classified quotes. We can observe that the percentage of correctly predicted True and Barely True quotes increased to 40% and 12% respectively. As for Pants on Fire, the model’s ability to correctly predict quotes from this class remained relatively constant. The spread of the coloration in the graph demonstrates a positive effect of balancing the class weights, as it allows to increase the recall of categories with fewer data points.
Binary Classification
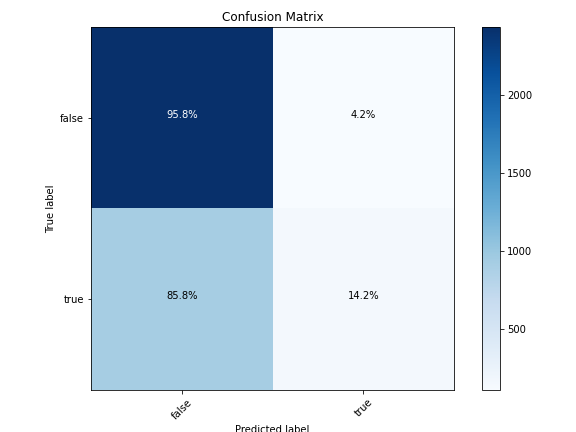
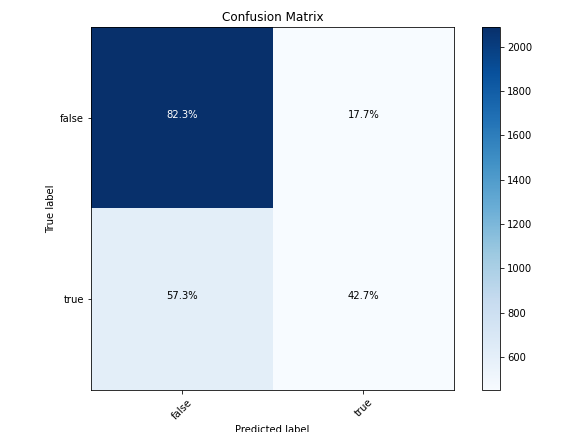
The same experiment was conducted on the binary labels which showed similar results. The adjustments to class weights had a significant impact on the classification of True quotes. For instance, as shown by the confusion matrices in Figure 7 and Figure 8, just by adjusting the weight of True labels and balancing the classes, the recall value for the True category increased by almost 30% while the recall for the False labels decreased by a less significant percentage at around 13%. Similar to the multi-class results, the same impact was observed for every classifier included in our experiments. An overview of the performance for each algorithm using binary labels is summarized in Table 2.
| Imbalanced | Weighted Labels | |||||
|---|---|---|---|---|---|---|
| Models | Accuracy | False Recall | True Recall | Accuracy | False Recall | True Recall |
| Naive Bayes | 0.689 | 0.816 | 0.378 | 0.665 | 0.726 | 0.521 |
| Logistic Regression | 0.710 | 0.915 | 0.229 | 0.671 | 0.719 | 0.557 |
| Random Forest | 0.709 | 0.990 | 0.050 | 0.682 | 0.754 | 0.514 |
| SVC | 0.708 | 0.972 | 0.089 | 0.679 | 0.719 | 0.586 |
| CNN | 0.714 | 1.000 | 0.000 | 0.686 | 0.730 | 0.500 |
| LSTM | 0.716 | 0.960 | 0.140 | 0.705 | 0.820 | 0.430 |
We observe that LSTM generated the highest accuracy in both the original imbalanced classes and the adjusted weights approach, with accuracy values of 0.716 and 0.705 respectively. The Naive Bayes algorithm yielded the highest recall for True quotes, while sacrificing overall performance with the lowest accuracy at 0.689. On the contrary, CNN resulted in the highest recall for False quotes in the imbalanced approach, but achieved a True recall of 0.00, essentially classifying all quotes as being False, which is very poor performance. We observe that the percentage of correctly classified True labels did not exceed Naive Bayes’ result at 0.378 in the imbalanced approach. By adjusting the weights and balancing the two classes, the percentage of correctly classified True quotes increased to a maximum of 0.586 with SVC, but once again sacrificing overall prediction accuracy.
Discussion
For each algorithms, we tuned the hyper-parameters to get the best possible results from each of the classifiers. Over-fitting was a recurrent issue, as the models were often perfectly classifying the training set while having poor accuracy on unseen data. For Deep Learning models, the structure of the network was vital, as we tried to find the structure that would fit our data in an optimal way. However, as seen in Table 2, the models were basically classifying the majority of our data as False. Therefore, our approach was to try to balance the results, and overcome the inherent problem of imbalanced data. We tried multiple solutions, such as over-sampling the true labels by duplicating quotes, but it encouraged overfitting and our classifiers ended up being biased. We also tried to remove the excess samples labeled as False, but getting rid of over 5000 data samples was counterproductive and our classifiers had less data to work with, which ended up giving poor results. The solution that showed the best trade-off in accuracy and recall was to add class priors which emphasized some labels by using weights. Every classifier reacted differently, so we tried to tune each prior according to each classifier. We ended up getting much less false negative results, producing classifiers with a slightly lower accuracy that were not only classifying the majority of quotes to False. In Table 2, the summary of the results shows that our best model obtained a better accuracy than the various accuracy scores provided in the related work studies. Since the number of quotes in Politifact increases everyday, we had the advantage of having more data, which undoubtedly contributed in the increase in performance of our models.
Limitations
As demonstrated by the results from our experimentation, the imbalance in our data set was a major issue and was hurting the performance of the models. We often ended up with either a classifier that predicts nearly everything as False or some balanced classification with pretty average results due to very few True samples in comparison to the number of False statements. The results showed that by adjusting the class weight for imbalanced datasets, the recall of each class can be balanced accordingly. By nudging the penalties of the underrepresented classes, it helps the models provide more insightful predictions despite a slight decrease in overall performance. However, the imbalanced nature of the data cannot fully be resolved through this method, as performance seems to suffer from this trade-off.
Future Works
One of the simplest solution to the problem of imbalanced classes would be to obtain more quotes from the underrepresented category. However, given that Politifact is a fact-checking, there is an inherent bias leading to more False quotes being verified as compared to True. A potential remedy to this limitation would be to extract more information from additional external fact-checkers such as Snopes or Google Fact Check and to consolidate all the data together. Collecting data from a variety of different sources could also improve the versatility of the models, such that different types of quotes from various categories, other than political, could be correctly classified.
In terms of model training, the implementation of more sophisticated algorithms could be explored. For instance, using the pre-trained GloVe models from Google could potential result in higher accuracy, as the unsupervised algorithm trains on a large corpus of textual data12. Likewise, we can also experiment with transformer-based algorithms such as Bidirectional Encoder Representations from Transformers (BERT)6.
Conclusion
In this post, we explored the classification of quotes from the Politifact fact-checking website. The results obtained from our experiments were quite similar to other studies, with LSTM yielding the highest accuracy values for both multi-class and binary approaches, with scores of 0.705 and 0.716 respectively. By tuning the weights for imbalanced classes, we obtained significantly higher prediction results for the underrepresented groups, at the expense of a slight decrease in overall performance.
References
- Gender-guesser
- Pickle - Python object serialization.
- Politifact
- Mariette Awad and Rahul Khanna. 2015. Support Vector Machines for Classification. 39–66.
- Arden Dertat. 2017. Applied Deep Learning - Part 4: Convolutional Neural Networks.
- Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2018. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.
- J. Feng, H. Xu, S. Mannor, and S. Yan. 2014. Robust logistic regression and classification. Advances in Neural Information Processing Systems 1 (01 2014), 253–261.
- A. Jain and A. Kasbe. 2018. Fake News Detection. In 2018 IEEE International Students’ Conference on Electrical, Electronics and Computer Science (SCEECS). 1–5.
- Dhruvil Kasani. 2018. Introduction to Word Embedding and Word2Vec
- Marija Kekic. 2017. CNN in keras with pretrained word2vec weights
- Rei Nakano. 2017. Basic NLP: Bag of Words, TF-IDF, Word2Vec,LSTM.
- GloVe: Global Vectors for Word Representation
- Arnu Pretorius, Surette Bierman, and Sarel Steel. 2016. A metaanalysis of research in random forests for classification. 1–6
- Kai Shu, Deepak Mahudeswaran, and Huan Liu. 2018. FakeNewsTracker: a tool for fake news collection, detection, and visualization. Computational and Mathematical Organization Theory 25, 1 (Oct. 2018), 60–71.
- Kai Shu, Deepak Mahudeswaran, Suhang Wang, Dongwon Lee, and Huan Liu. 2018. FakeNewsNet: A Data Repository with News Content, Social Context and Spatialtemporal Information for Studying Fake News on Social Media.
- Ralf C. Staudemeyer and Eric Rothstein Morris. 2019. Understanding LSTM – a tutorial into Long Short-Term Memory Recurrent Neural Networks.
- Steni T S and SREEJA P S. 2020. Fake News Detection on Social Media-A Review. Test Engineering and Management 83 (04 2020), 12997–13003.
- William Yang Wang. 2017. "Liar, Liar Pants on Fire": A New Benchmark Dataset for Fake News Detection
- Jiawei Zhang, Bowen Dong, and Philip S. Yu. 2018. FAKEDETECTOR: Effective Fake News Detection with Deep Diffusive Neural Network